
Improving AS-Level Topology Data Quality: A Summer at IPinfo

Get Unlimited Access to IPinfo Lite
Start using accurate IP data for cybersecurity, compliance, and personalization—no limits, no cost.
Sign up for freeHello! My name is Alagappan, and I am a PhD candidate in the Department of Computer Science at the University of California, Irvine. My research focuses on Internet measurements, specifically wide-area Internet measurements, where I work to understand the dependencies and impact of external factors across multiple layers of the Internet.
I joined the IPinfo research team this summer as a research intern, working remotely from July to September 2025. It has been a great experience working with the team, and in this blog post, I will summarize our findings and the work I accomplished during my internship. You can also find my other blog post about A Day in the Life of an IPinfo Research Intern if you're curious about what my daily work schedule looked like.
The Challenge: Uncovering Topology Anomalies
My internship focused on uncovering topology anomalies at the AS layer — inconsistencies, gaps, and errors in how IP addresses are mapped to their origin autonomous systems (ASes). Accurate IP-to-AS mappings are fundamental to understanding Internet topology: they tell us which network owns which IP addresses, enabling everything from routing analysis to security investigations.
The challenge was identifying where anomalies exist in IPinfo's current mappings and developing a systematic approach to improve mapping robustness. To tackle this, I compared IPinfo's IP-to-AS mappings against an independent, well-established topology inference algorithm that uses active measurements to build a view of network topology, providing an excellent reference point for validation.
My work had two main components: first, systematically analyzing the differences between the two datasets to understand patterns in data quality issues; and second, integrating this inference approach within IPinfo’s infrastructure to provide an additional source of topology data that continuously improves mapping robustness.
Finding the Gaps: A Data Quality Detective Story
To understand where anomalies exist, I compared IPinfo's existing IP-to-AS mappings with the inference algorithm’s results. I visualized the data quality issues using bubble plots, where the X-axis shows the percentage of missing or mismatched data, the Y-axis shows AS Rank (a measure of network size and importance based on how many customer networks depend on it), and bubble size represents the number of affected IP addresses.
The Missing Data Problem
The first analysis revealed an expected pattern: smaller networks (low AS rank) had the highest rates of missing data. These networks often have less visibility in measurement datasets and may not be well-represented in various data sources. No surprises there.
But then came the interesting discovery: some high-ranked ASNs — major networks that are critical to Internet infrastructure — had non-trivial rates of missing data when compared against the reference algorithm. These are networks with large customer bases, and understanding these gaps helped us prioritize where to focus our data quality improvements.
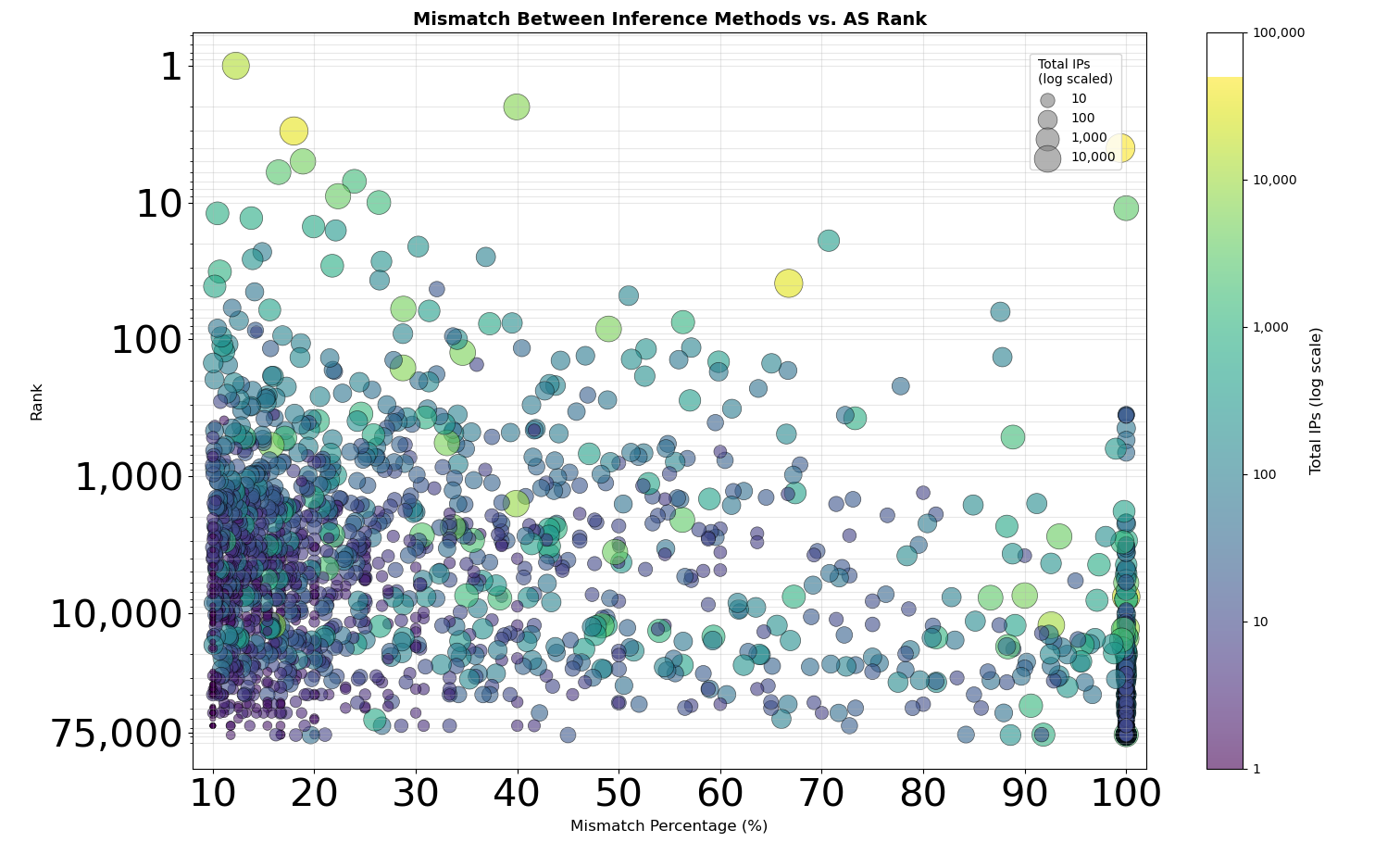
The Mismatch Problem
Beyond missing data, I investigated cases where our two data sources provided conflicting information about the same IP addresses. The analysis revealed several important patterns:
Relationship Complexity: The complexity of inter-network relationships played a significant role in where mismatches occurred. Operational practices like address leasing and multi-entity routing arrangements create inherent ambiguity that different inference approaches interpret differently. This is a well-known challenge across the industry.
Size Patterns: Both large and small networks showed mismatch patterns, though for different reasons. Smaller networks are harder to measure accurately due to limited visibility, while larger networks often have complex operational arrangements that create legitimate ambiguity in ownership attribution.
Key insight: Accurate topology inference requires combining multiple methodologies and data sources, because no single approach captures the full complexity of real-world network relationships.
The Solution: Integrating a New Inference Source
Based on this analysis, we determined that incorporating an additional inference methodology directly into IPinfo’s data pipeline could help fill gaps and resolve conflicts. The approach we chose is well-regarded in the research community for its sophisticated multi-phase process: mapping IP addresses to networks, annotating network boundaries, and iteratively refining inferences through a consensus mechanism.
Building the Integration
The major accomplishment of this internship was adapting the inference algorithm to work natively within IPinfo’s existing infrastructure, making it scalable while preserving the algorithm’s inference capabilities.
The integration involved three phases: building the foundational data structures for inference, implementing initial annotations using established heuristics for network boundary detection, and developing an iterative refinement process where inferences are progressively improved until the system converges. The engineering challenge was adapting a research algorithm designed for one type of computational environment to work efficiently at a production scale within our existing systems.
In my experiments, the algorithm showed steady progress toward convergence over iterations, with changes decreasing over time as expected.
Making It Production-Ready
Beyond getting the algorithm to work correctly, a crucial part of making this practical was ensuring it could run sustainably at scale. I analyzed computational costs, storage requirements, and scalability trade-offs to ensure the implementation was economically viable for continuous production deployment. It’s one thing to make an algorithm work — it’s another to make it sustainable at scale.
Real-World Impact
The new inference source is being integrated within IPinfo’s data pipeline, where it provides additional AS relationship inferences that complement existing data sources. This integration enables several practical improvements:
Better Coverage: The algorithm fills in gaps identified in my analysis, particularly for smaller networks that were previously under-represented. By incorporating additional traceroute-based inferences, IPinfo can provide mappings for IP addresses that previously had missing or uncertain AS assignments.
Conflict Resolution: When different data sources disagree, having multiple perspectives helps identify which relationships are most likely correct. High-confidence cases (where sources agree) can be trusted more, while conflicts can be flagged for further investigation.
Continuous Improvement: Because the implementation runs natively in IPinfo's infrastructure, it can be updated regularly as new measurement data becomes available, ensuring topology data stays current without manual intervention.
Scalability: The implementation runs within IPinfo’s existing data infrastructure, eliminating the need for separate processing systems or manual import workflows.
For IPinfo's users, including network operators, researchers, security analysts, and anyone who needs accurate Internet topology data, this means more complete and reliable information about how networks connect and relate to each other.
Lessons Learned
This internship taught me several valuable lessons about working with Internet topology data at scale:
Multiple Perspectives Are Essential: Comparing different data sources and inference approaches revealed gaps and conflicts that wouldn't be visible from either source alone. The combination provides a more complete picture than relying on a single methodology. Understanding where different approaches agree and disagree is crucial for building confidence in the data.
Size Isn't Everything: While smaller networks consistently showed data quality issues, discovering significant gaps in major networks was a reminder that even critical infrastructure can have surprising blind spots. Data quality efforts need to address both coverage and accuracy.
Adapting Research to Production: One of the most interesting technical challenges was adapting an algorithm designed for a research context to work efficiently at a production scale. The key is understanding both the algorithm’s underlying logic and the target system’s strengths, then finding creative ways to bridge the gap.
Trade-offs Are Everywhere: Every design decision involves balancing accuracy, scalability, cost, and maintainability. Understanding these trade-offs is crucial for building systems that actually get used in production.
Building More Robust IP-to-AS Mappings
Uncovering topology anomalies at the AS layer is an ongoing challenge. Networks constantly evolve, new connections form, old ones disappear, and operational practices like IP leasing and multi-entity BGP announcements create inherent complexity in IP-to-AS mappings. But by systematically analyzing where anomalies exist, considering factors like network size, relationship complexity, and comparing multiple inference approaches, we can build more robust mappings.
My internship at IPinfo contributed to this effort in two ways: first, by identifying specific patterns in topology anomalies and understanding their root causes, and second, by developing a practical solution that provides IPinfo with an additional inference source for IP-to-AS mappings, helping to uncover and address anomalies within the existing infrastructure.
As the Internet continues to grow and evolve, maintaining robust IP-to-AS mappings will remain crucial for anyone seeking to understand how the Internet actually works. I'm grateful to have contributed to this effort during my time at IPinfo, and I look forward to seeing how this work helps uncover topology anomalies for users in the months and years ahead.
Share this article
About the author

Alagappan is a 2025 IPinfo Research Intern. He's also a fourth-year PhD student in the Department of Computer Science at the University of California, Irvine, where he focuses on wide-area Internet measurements.